
Open data essentials for research managers and administrators
How confident do Research Managers and Administrators (RMAs) feel when talking to researchers about open data? According to F1000 polling at the latest European Association of Research Managers and Administrators (EARMA) conference, RMAs responses to this vary. However, the average result leaned towards the less confident side of the spectrum.
Given that open data and its processes are increasingly forming a large part of RMAs’ roles, we hosted a webinar in collaboration with EARMA on the what, why, and how of open data. In this session, we shared the publisher’s perspective on the basics of open data to help the RMAs who were less comfortable supporting researchers to share their data.
Watch our on-demand webinar below, or keep reading for the key takeaways.

What is open data?
Open data is data that is available for everyone to access, use, and share. This means the data is stored somewhere public, like a repository, so anyone can find, read, and reuse the data, which an open license enables. When most people hear ‘data,’ they tend to think of spreadsheets and numbers—quantitative data. However, the format of your data depends on your research discipline. For example, research data in the humanities and social sciences are often qualitative, such as images, audio, or transcripts.

Common misconceptions researchers have about open data
Misconception #1: “I don’t have any data to share.”
Some researchers, particularly in the arts and humanities, think they don’t have any data to share from their research. The truth is research data exists in many forms. Data includes textual, geospatial, images, audio-visual recordings, and even data generated by machines or instruments.
Misconception #2: “Data sharing isn’t relevant in my field.”
Despite data sharing not being the norm in some disciplines, the benefits of open data supporting the potential reuse of research and reproducibility remain the same.
Misconception #3: “Someone else could scoop my research if I share my data.”
On the contrary, data sharing establishes ownership through persistent identifiers, timestamps, and links to the authors. When a researcher deposits their data in a public repository, they have established that they are the creator of the dataset and should receive credit for it.
Misconception #4: “Data sharing is too complicated and time-consuming.”
It does not have to be this way! Publishers like F1000 want to help researchers with clear data sharing guidelines and resources.
How F1000 supports open data: Two case studies
F1000 is at the forefront of open data sharing as an academic publisher. In 2013, we launched the industry’s first mandatory open data policy with our F1000Research Platform. In 2016, we signed our first funder partnership with Wellcome, launching Wellcome Open Research using the F1000 model and open research practices. Today, we have 16 Platforms, all with mandatory open data policies.
Case study one: Data sharing on Open Research Europe
Launched in 2021 in collaboration with the European Commission and powered by F1000, Open Research Europe was motivated by the European Commission’s ambition to establish an open research platform that leads by example, including an open data policy. By providing a Platform specifically for Horizon 2020, Horizon Europe, and Euratom grant beneficiaries, Open Research Europe ensures researchers comply with their funding mandates and that data shared is ‘as open as possible, and as closed as necessary.’ Our editorial team checks submitted manuscripts for compliance with the relevant funding policy requirements and the ORE Publishing Platform. These checks ensure that the data has been shared openly in an appropriate repository and according to relevant standards.
Case study two: Data sharing on Routledge Open Research
Explicitly developed for Humanities and Social Science (HSS) researchers, F1000 developed Routledge Open Research (ROR) in partnership with Routledge. ROR is the first F1000 Platform to have open data guidelines explicitly tailored to researchers in HSS.
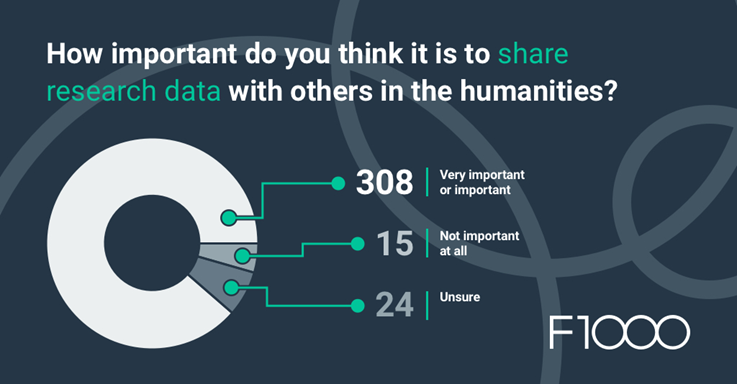
Humanities researchers are often less experienced in data sharing practice and may be unsure how to address copyright issues when using third-party sources, for example, from archives or museum collections. A survey in The State of Open Data 2022, co-authored by Dr. Rebecca Grant (Head of Data and Software Publishing at F1000), revealed that many humanities researchers were also concerned about sharing sensitive information and data misuse. In addition, humanities researchers tend to share data with other researchers on a peer-to-peer basis (for example, via email) rather than publicly through repositories.
Researchers in the Social Sciences may also find data-sharing challenging when working with human participants, particularly when researching sensitive topics. Our open data policy acknowledges that public data sharing may not always be appropriate for sensitive datasets and encourages best practice alternatives, such as anonymization and using controlled-access repositories where appropriate.
Although data sharing practice is not yet the norm in the humanities and social sciences, we believe that the provision of tailored HSS open data guidelines, like on Routledge Open Research, can encourage the increased sharing of rich datasets.
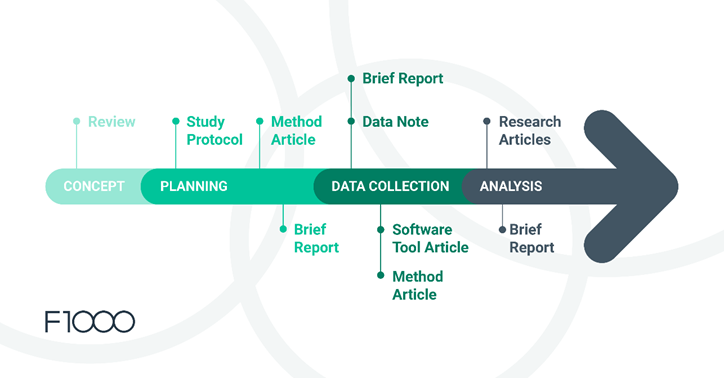
How researchers can share their data in 4 simple steps
1. Prepare the data
Firstly, we recommend researchers consult FAIRSharing.org for advice on data standards specific to their research area. When depositing data involving human participants, F1000 Platforms ask authors to ensure all datasets have been de-identified where necessary before submission. It is also important to label all files clearly to ensure readers understand the contents of each data file and for research to follow best practices depending on the file format.
2. Choose a data repository
When selecting a repository, researchers should check the following:
- Whether other researchers in the same discipline use the repository
- Whether the repository guarantees storage for a particular length of time
- Whether DOIs will be assigned to their data set to ensure it can be cited and found
- What metadata format the repository uses to ensure the data is labeled effectively
- Whether there is a cost for storage and how that will be covered. There are a lot of free repositories, but that does not mean they are the best ones
- Whether the repository meets the FAIR principles. You can check F1000’s data policy guidelines to see if it is on our recommended list.
3. Deposit the data
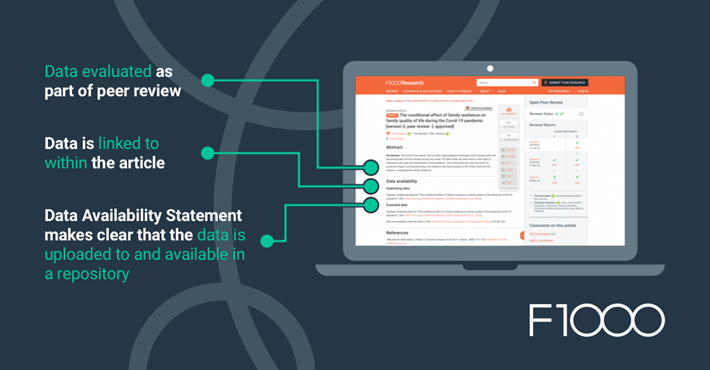
We encourage researchers to deposit their data as early as possible, so it receives accreditation and can be built upon by others early on. We also encourage researchers to publish Data Notes, usually short essays allowing researchers to add supplementary descriptions to their data. Data Notes enable people to understand the data set for itself, enhancing its reusability, separate from the Research Article, which usually comes at the end of the research project.
4. Link the data
Finally, the last step of data sharing is for researchers to include a Data Availability Statement with their article. A Data Availability Statement allows researchers to link to their data in a repository and state the license under which their data is, helping reviewers and readers access the underlying data. Once an article is published, it is also a good idea for researchers to link to their article from the data repository record itself. Each component is connected and discoverable, ensuring researchers receive credit for their work.
At F1000, we encourage researchers to be transparent with their data, and our Platforms offer clear guidance on how to do this. As a result, both reviewers and readers of the research can access the same source materials as the researcher, supporting research reusability, reproducibility, and credibility.
Want to continue learning about open data? Visit our online hub of downloadable resources on Data Availability Statements, repositories, spreadsheets, and data collection tips and tricks.